الرئاسة الفلسطينية تُدين العدوان الإسرائيلي على طولكرم ومخيميها
أعربت الرئاسة الفلسطينية، الجمعة، عن إدانتها الجريمة الجديدة التي ارتكبتها قوات الاحتلال الإسرائيلي...
أعربت الرئاسة الفلسطينية، الجمعة، عن إدانتها الجريمة الجديدة التي ارتكبتها قوات الاحتلال الإسرائيلي...

- فيما يخص مشكلة الكهرباء في العاصمة عدن فهي متشابكة ومتشعبة وتتصاعد في ظل التوسع العمراني وتزايد عد...

من المقرر أن تصل الى العاصمة عدن يوم السبت سيدة هندية محكوم على ابنتها بالإعدام في مناطق سيطرة الحوث...
قام باحثون من معهد ماساتشوستس للتكنولوجيا، بابتكار خوارزمية ينتظر منها أن تفهم الإشارات الاجتماعية المرئية عند البشر، والتنبؤ بما سيحدث بعدها. إن منح الذكاء الاصطناعي القدرة على فهم التفاعلات الاجتماعية عند البشر والتنبؤ بها، قد يمهد الطريق يوماً ما نحو ابتكار أنظمة فعالة للمساعدة المنزلية، بالإضافة إلى كاميرات المراقبة الذكية، التي يمكنها الاتصال بالإسعاف أو الشرطة في وقت مبكر.
كيف يجعلك التلفاز أكثر ذكاء؟
قام مختبر علوم الحاسوب والذكاء الاصطناعي في MIT، بابتكار خوارزمية تستخدم تقنيات التعليم العميق، التي تمكن الذكاء الاصطناعي من استخدام نماذج التفاعل البشري، للتنبؤ بما سيحدث لاحقاً. حيث قام الباحثون بتغذية البرنامج بمقاطع فيديو تظهر مجموعة من التفاعلات الاجتماعية عن البشر، واختبروه بعد ذلك ليعلموا ما إذا كان قد "تعلّم" جيداً بما يكفي ليكون قادراً على التنبؤ بها.
ما هي أسلحة الباحثين المفضلة؟ 600 ساعة من الفيديوهات والمسلسلات الفكاهية التي يعرضها يوتيوب، تتضمن، "ذا أوفيس"، "ديسبريت هاوس وايفز"، و"سكرابس". في حين قد تبدو هذه القائمة مشكوكاً فيها، فإن طالب الدكتوراه في MIT، ومسؤول البحث في هذا المشروع، كارل فوندريك، يبرر ذلك بأن سهولة الوصول والواقعية تشكلان جزءاً من المعايير.
ويقول فوندريك؛ "أردنا فقط استخدام فيديوهات عشوائية من يوتيوب. وسبب لجوئنا إلى التلفاز، هو سهولة الوصول إلى تلك البيانات، وهو واقعي إلى حد ما من ناحية وصفه للمواقف اليومية".
لقد عرضوا على الحاسوب فيديوهات لأشخاص على بعد ثانية واحدة من القيام بأحد هذه الأفعال الأربعة: العناق، التقبيل، ضرب شخصين متقابلين لكفيهما high-five، والمصافحة. وقد تمكنت خوارزمية الذكاء الاصطناعي من التخمين بشكل صحيح على 43% من الحالات، مقارنة مع الأشخاص الذين أصابوا في 71% من الحالات.
مستقبل مرتقب
منح الذكاء الاصطناعي القدرة على فهم التصرفات المرئية للبشر، قد يكون مقدمة لأنظمة فعالة في تقدم المساعدة المنزلية، إضافة إلى كاميرات المراقبة الذكية، التي يمكنها الاتصال بالإسعاف أو الشرطة في وقت مبكر.
في حين أن هذه المحاولة ليست الأولى من نوعها للتنبؤ بالفيديو، إلا أنها الأكثر دقة حتى الآن. ويعود السبب إلى أن، أولاً، الخوارزمية الجديدة تختلف عن المحاولات السابقة للتنبؤ بالفيديو، حيث كانت تشكل التمثيلات بيكسل-تلو-الآخر أولوية في المعالجة. فهي تتنبأ باستخدام تمثيل مجرّد، وتركز على الإشارات الهامة: إنها تتعلم بنفسها، وتستخدم "التمثيلات المرئية" لتميز الإشارات المرئية التي تعتبر هامة في التفاعلات الاجتماعية، عن الإشارات غير الهامة. إنه أمر يكتسبه البشر بشكل طبيعي، ولكنه في غاية التعقيد في الذكاء الاصطناعي.
وفي هذا الصدد، يقول بيدرو دومينغوز، خبير التعلّم الآلي والأستاذ في جامعة واشنطن؛ "ليس هنالك اختلاف كبير عما قام به الآخرون. ولكنهم حصلوا على نتائج أفضل بكثير مما حققه الآخرون في هذا المجال من قبل".
المصدر: NPR.org
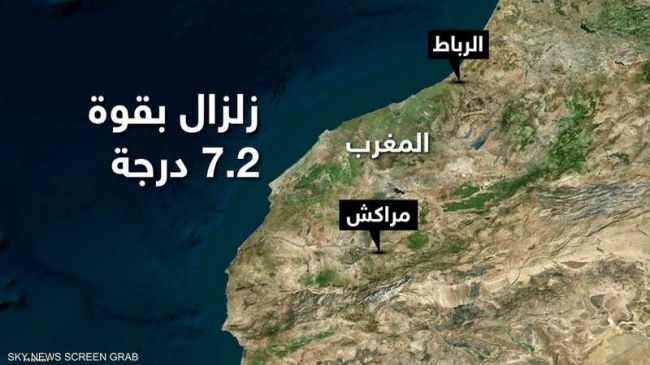
ضرب زلزال قوي ونادر المغرب، ليل الجمعة السبت، ما أسفر عن مقتل وإصابة ا...
يتفق خبراء الصحة على أن قطاع التكنولوجيا العصبية يشهد نموا سريعا ويفتق...

بناء على تقارير لمراكز بحوث مختلفة فان مركز أبحاث السرطان في من...